Microsoft's flagship database is an important tool, with local and in-cloud versions offering powerful archiving and analysis tools. It also becomes an important application for data scientists, providing a framework for the construction and testing of machine learning models. There's a lot in SQL Server, and a new version can show you where Microsoft thinks your data needs will go in the next few years.
The latest CTP for SQL Server 2019, version 2.1, is now available to help evaluate and test the next version outside of production environments. Like its predecessor, it is available in Windows and Linux versions, although support for containers and Kubernetes has now been added. Adding container support, using Docker and the Linux version of SQL Server, is an interesting option as it allows you to create SQL Server in huge analytical engines based on Kubernetes that work with data lakes hosted by Azure using Apache Spark .
The current preview installer offers the option of a basic, quick and fast installation or a more detailed custom installation. The first option requires less disk space because they are the files needed to perform the basic installation, while a custom installation reduces the entire installation support of SQL Server 2019. For most of the basic development tasks it is a basic installation is sufficient, although we recommend a custom installation as part of a complete evaluation. You can also download the installation media if you plan to install it on more than one computer to evaluate the capabilities of the SQL Server cluster.
Machine learning is an important part of SQL Server 2019 and now includes integrated tools for creating and testing machine learning models. You can install it with support for the popular R and Python languages, so your data science team can work within the database, prepare and test models before you can format them on your data. Microsoft is using its own Open R distribution and the Anaconda Data Science Python environment, which includes additional numerical analysis libraries, including the popular NumPy.
You can also install SQL Server 2019 as a self-learning environment for machine learning. Local SQL Server instances on developer workstations will be able to use R and Python familiar tools to work directly with training datasets, without affecting production systems or server resource utilization.
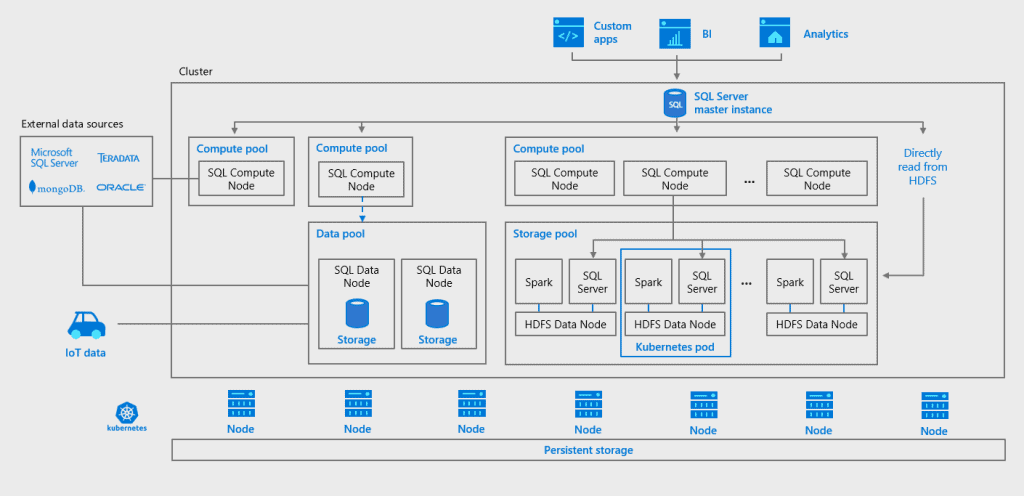
Really BIG data
Working with large-scale data has long been a problem, with very few database engines designed to function as part of a distributed architecture. With SQL Server 2019 it is now possible to create what Microsoft calls Big Data Clusters, using a mix of SQL Server and Apache Spark containers on Kubernetes using the existing PolyBase capabilities of SQL Server. With public clouds that support native Kubernetes, you can deploy Big Data Clusters on Azure, AWS, and GCP as well as your infrastructure. Integration with Azure Data Studio tools simplifies the creation, execution and sharing of complex queries.
Microsoft's focus on data science scenarios fits perfectly with the intelligent cloud / business intelligence strategy. Data is essential to create machine learning tools and, by executing R and Python code within the database, it is possible to send complex queries from the SQL Server command line, using familiar tools to create and test the code before distributing and executing it. . Microsoft is providing sample code through GitHub, which shows how to combine relational data with big data. It also shares sample architectures that show how to use this as a basis for the creation of machine learning systems as well as open source technologies such as Kafka.
Other new features, such as static data masking, focus on protecting and disinfecting data so that they can be used without affecting regulatory compliance. The application of static masking of data to columns in the export of a database allows developers to work with real data and avoid loss of sensitive information. There is no way to recover the original data, as it is a one-way process. Previous versions of SQL Server introduced dynamic data masking, which works only with the original database. Exporting with static masking there is little or no risk for developers to unmask or randomly alter data in real time, leaving them to produce code that can be put into production without any modification.
At the database level, when you create indexes you can now stop and start. If a disk is being filled, you can pause an indexing operation, add more memory to the volume, and then resume from where it left off. It is not necessary to start from scratch, saving time and calculations. There is also the possibility to reboot after errors, saving more time after correcting the error that caused an index to crash.
With SQL Server 2019, Microsoft is proving that even though relational databases have been around for a long time, there is still room for improvement and innovation. Building a database engine that works like every SQL Server has worked in the past, while supporting the work with machine learning and large amounts of data on a large scale, offers a tool ready to update what you have and to support you as work with your data securely, locally and in public clouds. All you have to do is download it and see what it can do for you.